Exponential Mechanisms - What's Wrong with Sensitivity?
\(\newcommand{\ep}{\varepsilon} \newcommand{\Exp}{\mathrm{Exp}}\)
A private mechanism $M:X\to Y$ is often designed as a slight perturbation of what is truly wanted. This is straightforward if $Y=\mathbb{R}^d$ — just add Gaussian (or your favorite) noise. What if $Y$ is a finite, unstructured set? The classical tool is exponential mechanism. Since $Y$ is no longer equipped with a metric, we need an additional structure: the quality score $q: X \times Y \to \mathbb{R}$. The score $q(x,y)$ measures how good the item $y$ fits dataset $x$. The better $y$ fits $x$ the higher $q(x,y)$ is. Traditionally, the sensitivity of the quality score $\mathrm{sens}(q):= \max_{y \in Y} \max_{x \sim x’} | q(x,y) - q(x’,y)|$ plays a crucial role in the theory.
Definition A randomized algorithm $\Exp_{q,\varepsilon}:X\to Y$ is called the exponential mechanism with quality score $q$ and parameter $\varepsilon$, if the outcome $y$ is sampled with probability proportional to $\mathrm{e}^{\varepsilon q(x,y)}$, i.e.
\[P[\Exp_{q,\varepsilon}(x)=y] = \frac{\mathrm{e}^{\varepsilon q(x,y)}}{\sum_{y\in Y} \mathrm{e}^{\varepsilon q(x,y)}}.\]Theorem 0 [McSherry-Talwar ‘07] $\Exp_{q,\varepsilon}$ is $2\mathrm{sens}(q)\cdot\varepsilon$-DP.
Neat, huh? Here’s an example. Let $X=Y=\{0,1\}$ and $q(x,y) = x+y, q’(x,y) = 100x+y$. Clearly $\mathrm{sens}(q)=1$ and $\mathrm{sens}(q’) = 100$. On the other hand, you can easily verify that they lead to the same mechanism, i.e. $\Exp_{q,\varepsilon} = \Exp_{q’,\varepsilon}$. Intuitively, $q$ and $q’$ are not that different – they just start with different grounds. Two items $y_1$ and $y_2$ look equally different from the perspective of $q$ and $q’$, because the difference of the quality scores $q’-q$ is independent of the variable $y$.
So even though Alice and Bob are running exactly the same algorithm, they may end up with arbitrarily different privacy conclusions using Theorem 0. Mathematically this already makes no sense. On the practice side, Bob can severely underestimate the privacy that he already has. In that unfortunate case, he either reports very weak privacy guarantee, or increases the noise level and ruins the accuracy.
To the rescue, you may try to find the least sensitive quality score that leads to the same mechanism. A first guess could be that $q(x,y) = \log P[M(x)=y]$ is always the least sensitive score that realizes a given mechanism $M$, but it’s not true.
Root of All Evil
In analogy to sensitivity, we define a quantity called range to resolve the problem.
\begin{align}
\mathrm{sens}(q)&:= \sup_{x\sim x’} \max_{y} |q(x’,y)-q(x,y)|\\
\mathrm{range}(q)&:= \sup_{x\sim x’} (\max_y - \min_y) [q(x’,y)-q(x,y)].
\end{align}
Here is the new privacy theorem in terms of range. We also put Theorem 0 above it for ease of comparison.
Theorem 0 [McT ‘07] $\Exp_{q,\varepsilon}$ is $2\mathrm{sens}(q)\cdot\varepsilon$-DP.
Theorem 1 [DDR ‘19] $\Exp_{q,\varepsilon}$ is $\mathrm{range}(q)\cdot\varepsilon$-DP.
Unlike its predecessor, this theorem concludes privacy about the mechanism instead of the quality score, because
Proposition If $\Exp_{q,\varepsilon}=\Exp_{q’,\varepsilon}$ then $\mathrm{range}(q) = \mathrm{range}(q’)$.
The new theorem is better not only semantically but also quantitatively.
- $\mathrm{range}(q)\leqslant 2\mathrm{sens}(q)$.
- $\mathrm{range}(q) = \mathrm{sens}(q)$ if $q$ is monotone, i.e. $q(x,y)\leqslant q(x’,y)$ if $x\subseteq x’$1. In particular, counting queries are monotone, with $\mathrm{range} = \mathrm{sens} = 1$.
In summary, Theorem 1 is never worse than Theorem 0, and two times better for a very general class of queries.
Practical Implications
The reasoning above was motivated by a practical question, which is discussed by my collaborator Ryan in detail here. Basically LinkedIn wants to answer queries from advertisers like “What are the most popular articles in the last 30 days among data scientists working in the San Francisco Bay area?” And yes, they decide to use differential privacy. These “top $k$” queries often come in batch2, and are most naturally answered by repeated use of exponential mechanisms (with twists that we ignore here). Accumulative effect on privacy, as usual, is handled by composition theorems.
So we need to analyze composition of exponential mechanisms. Before our work, the best analysis would use Theorem 0 and the optimal DP composition theorem (Opt DP Compo) from [KOV ‘15]. Our improvements come in two ways: 1) use range instead of sensitivity, 2) with the additional knowledge that each component is an exponential mechanism, it’s possible to improve on “Opt DP Compo.” In fact, we proved optimal composition theorems for exponential mechanisms (Opt Exp Comp).
Counting queries are the most common, so let’s assume that. For the same algorithm, i.e. $k$-fold composition of exponential mechanisms with parameter $\varepsilon$, the two analyses yield
\begin{align}
\text{Thm 0 + Opt DP Compo} &\Rightarrow \,\, \big(\varepsilon_{\mathrm{g}},\delta = \delta_{\mathrm{DP}}(\varepsilon,k,\varepsilon_{\mathrm{g}})\big)\text{-DP}\\
\text{Thm 1 + Opt Exp Compo} &\Rightarrow \,\, \big(\varepsilon_{\mathrm{g}},\delta = \delta_{\Exp}(\varepsilon,k,\varepsilon_{\mathrm{g}})\big)\text{-DP}
\end{align}
You can find the expressions of $\delta_{\mathrm{DP}}(\varepsilon,k,\varepsilon_{\mathrm{g}})$ and $\delta_{\Exp}(\varepsilon,k,\varepsilon_{\mathrm{g}})$ here and here, but I always find it challenging to understand their asymptotic behaviors. Here is something you can do if you are ok with asymptotics ($\varepsilon=O(1/\sqrt{k})$ as it should, and $k\to\infty$) and Gaussian Differential Privacy (GDP, see an introduction here).
{kind=link}
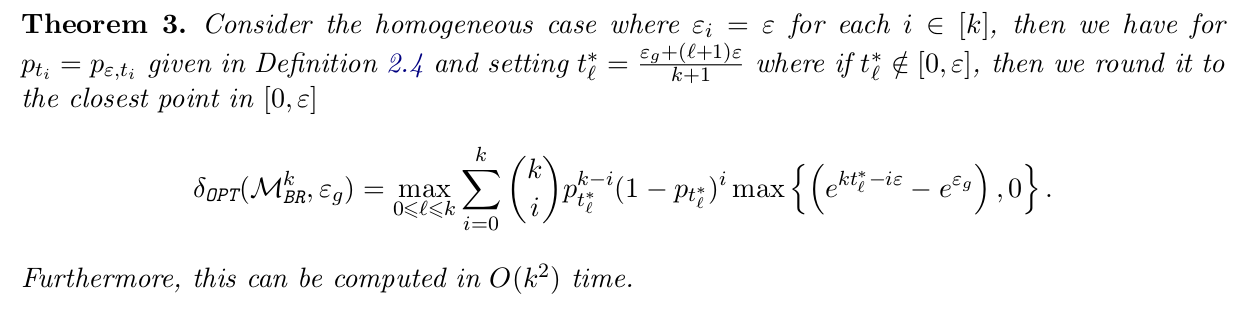{kind=link}
\begin{align}
\text{Thm 0 + DP CLT} &\Rightarrow 2\varepsilon\sqrt{k}\text{-GDP}\\
\text{Thm 1 + Exp CLT} &\Rightarrow \tfrac{1}{2}\varepsilon \sqrt{k}\text{-GDP}
\end{align}
These asymptotic results make it clear that fine-grained analysis can buy a factor of 4 in terms of privacy3. If we want to reach the same level of final privacy, then the improved (in fact, optimal) analysis allows us to answer 16$\times$ more queries. This can be crucial for DP at LinkedIn: advertisers are probably ok with 16 queries per day, but definitely not with 1 query per day.
Conclusion
- For exponential mechanisms, forget sensitivity. Use range.
- You can buy a factor of 4 in privacy parameters from classical analysis in composition of exponential mechanisms.
To find out more, check out this paper and its predecessor.
Notes
-
This relies on the neighboring model being add/remove. Notation in the post is for replace model for simplicity. ↩
-
In reality, queries come adaptively, i.e. the next query comes after the previous is answered. To keep the presentation accessible we assume the batch setting. ↩
-
Part of the achievement here comes from the previous paper of my collaborators David Durfee and Ryan Rogers. Comparison to this result is necessarily less accessible because of the complicated formula involved, which is why I choose to compare to the classical analysis in this post. ↩